Splunk Overview
Splunk is a tool which ingests any data generated by the IT systems and help you generate insights from it in the form of reports, dashboards and alerts. This blog will provide an overview of the Splunk while covering some capabilities for searching through the log events. Following are the three main functions performed by Splunk:
- Data input
- Parsing and indexing
- Parsing: Analyses data and annotates it with Splunk metadata
- Indexing: Takes the parsed annotated data and saves it in indexes in buckets
- Searching
We play around with the above functions to scale our systems.
Deployment Models
There are three types of deployment models provided by Splunk:
- Single Instance: Single search head also works as indexer. Up to 10 forwarders. Appropriate for up to 10 users
- Distributed
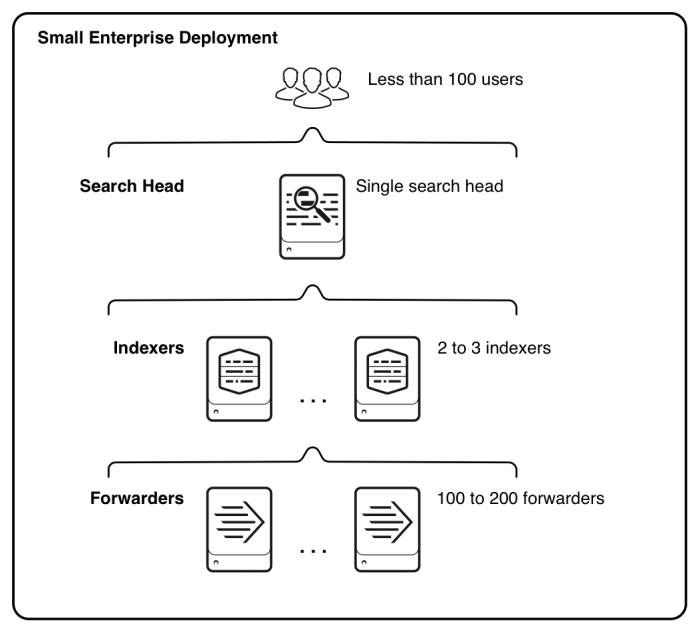
- Small enterprise deployment: We have single search head and 2-3 indexers and up to 200 forwarders
- Large enterprise deployment: We have a cluster each of Search Heads and indexers. They can support thousands of forwarders. It also has a deployer or deployment server
- Cloud
- Self serve: 20 GB of data ingestion, No AD (Active Directory) or No SSO (Single Sign-on). It allows 20 concurrent searches
- Managed: Custom configuration
Data Storage
Splunk transforms incoming data into events and stores them into indexes which act as a repository. The two indexes provided by default are:
- main: the default index
- _internal: for internal logs of Splunk
Consider Event as a single row of data or a record of a database table. The data in the row is stored as fields which is a key-value pair. Splunk adds the following default fields to each event:
- Timestamp: Load timestamp is used if incoming data doesn’t have a timestamp field
- Host: machine name
- Source: e.g. log file name
- Sourcetype: e.g. CSV, log file type, etc
The indexes data is stored in one of the following buckets depending on the recency of data:
- Hot
- Warm
- Cold
- Frozen
- Thawed
The data moves from Hot bucket to the lower buckets in the above order. Data moving into Frozen bucket can be archived so we can provide a custom location to it. Rest of the buckets have fixed location. The archived data goes into the Thawed bucket.
Splunk Apps
Splunk apps are collection of config files which are used to extend the functionality of Splunk. The ‘Search & Reporting’ app is a commonly used app. The apps can be downloaded from Splunkbase.com. The apps can be of following types:
- Built by Splunk so they are tagged ‘Splunk Built’
- Approved by Splunk but built by a third-party so they are tagged ‘Splunk Certified’
- Not approved by Splunk but built by a third-party so they are not tagged
Data Ingestion
Data can be ingested either as a standalone file or by setting up a pipeline for recurring data ingestion.
For standalone file simply use the ‘Add Data’ feature on Splunk console to load the file.
For setting up the pipeline of data you need to setup the forwarders and receivers. Forwarders are the agents which are responsible for sending the data from other systems to the Splunk receiver. The receiver is configured so that it can accept the data pushed by the forwarders.
The forwarder gathers a lot of information from the systems on which they are installed such as application log, system log, security log, CPU, memory, disk space, network stats, etc. The forwarders are of two types, Universal and Heavy. Universal Forwarders are the dumb forwarders used more commonly which forward all data to the receiver. The Heavy Forwarders are more intelligent and can do some heavy lifting at the source like data indexing, data parsing, load balancing, applying some specific routing rules, etc.
Search Processing Language (SPL)
SPL is a language used to query and extract insights out of the data ingested in Splunk. There is a ‘Search and Reporting’ app available by default in all Splunk installations. The Search App has three modes:
- Fast: Except the default fields it does not discover any other field so you need to provide the fields in the search string
- Smart: Returns best possible search results
- Verbose: It discovers all fields so it has to be used when you don’t know about the field to report
During the field discovery, Splunk identifies the key-value pairs. If the Splunk is not able to extract the fields, you can do it manually using the Field Extraction tool. It uses the regular expressions for defining an identified field.
The basic building blocks of SPL are:
- Keywords: Words having special meaning like TOP
- Phrases: Space separated text denoted within double quotes
- Fields: The keys used in Search string
- Wildcards: * is used as a wild card with search strings
- Boolean: For logical operation, AND, OR, NOT. They are case sensitive
Some important search commands:
- table: outputs a table with specified fields
- stats: used like a Group By function of query
- eval: to specify a custom field. For e.g. eval sum(amount) as HourlyRevenue by city
- sort: field name is appended with a – or + to control descending or ascending order respectively
- dedup: removes duplicates
- rename: to rename specific fields. For e.g. rename XYZ AS ABC
AS is used to specify alias in other commands as well like ‘stats’
- chart/timechart: returns tabular output for charting. For e.g.
- timechart span=1h sum(amount) as HourlyRevenue by city
Splunk also maintains a default timestamp information in _time field. You can define your own custom field based on the information you are interested from the timestamp field.
eval time=strftime(_time, “%I:%M”)
Refer to Splunk documentation for all available formatting options.
The search string starts with specifying the source and the fields and then using the pipe operator to filter the records from generic to more specific set of records. Finally, the data is either displayed as a table or visualized as chart.
Like a map-reduce paradigm, we need a finally reduce the set of filtered records into a collective information set. Following are some of the reduce commands:
- top: displays most common values of a field.
- For e.g. top limit=5 field-name
- rare: displays least common values of a field. For e.g. rare limit=5 field-name
- stats: perform a group-by operation. They are used with other commands like sum, count, etc. For e.g. stats sum(amount) as total by city
We have just touched upon the basic search capabilities which are used generally while searching through logs for troubleshooting a one-off issue. For standard operations, it is more common to save the search results as a scheduled report, or as an alert, or adding them to a new or existing dashboard by using the ‘Save As’ feature.
You should now register for a Spring Cloud account if you don’t have access to Splunk instance and try out searching through some sample CSVs.