Spark MLlib Data Types

Spark MLlib has special data types since in Machine Learning we normally have to deal with a binary distribution of vectors or matrix.
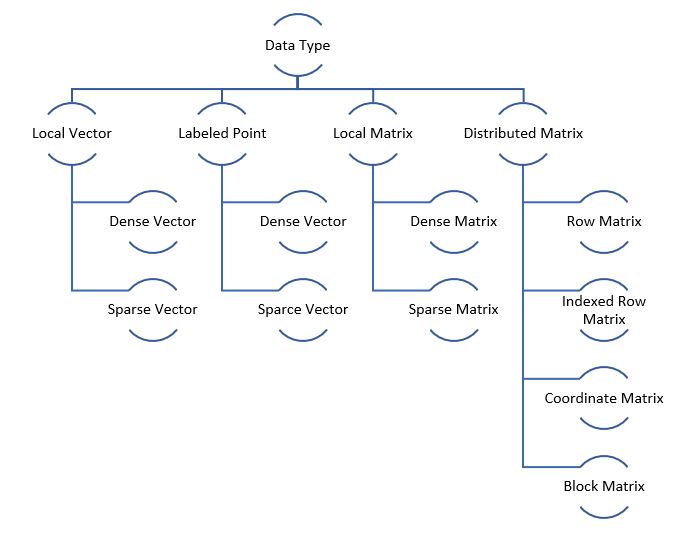
Spark MLlib Data Types
Note: Any sample code is following Scala syntax
| Overview | |
| Local Vector | A local vector has integer-typed and 0-based indices and double-typed values, stored on a single machine. MLlib supports two types of local vectors: dense and sparse. |
| Dense Vector | Dense vector has actual values represented in a double array.
E.g. vector (1.0, 0.0, 3.0) will be represented as [1.0, 0.0, 3.0]. Note: Only square bracket symbol of vector is changed Sample code:
|
| Sparse Vector | Sparse vector is a vector having very few values populated i.e. most of the values are 0 if 0 represents Null or Missing value. It is represented by two parallel arrays: indices and values.
E.g. vector (1.0, 0.0, 3.0) will be represented as (3, [0, 2], [1.0, 3.0]) where, 3 is the size of vector, first integer array [0, 2] contains the index points having null values and second array [1.0, 3.0] holds the exact values at those index locations. Sample code:
You can also specify a sparse vector in a (index, value) format as shown below. E.g. vector (1.0, 0.0, 3.0) will be represented as (3, Seq((0, 1.0), (2, 3.0))) where, 3 is the size of vector and pairs within the Seq block have only the reference to non-zero values in (index, value) format. Sample code:
|
| Labeled Point | It is a local vector which can be either dense or sparse. It is associated with a label/response which is nothing but the target values in a supervised machine learning dataset.
E.g.
|
| Local Matrix | It has integer-typed row and column indices and double-typed values and it is stored on a single machine. It also has two types: dense and sparse. |
| Dense Matrix | Same as dense vector but in matrix structure.
Sample matrix is as shown below having size (3, 2) will have the size specified followed by the array of values. The values will be listed column wise: 1.0 2.0 3.0 4.0 5.0 6.0 Sample code:
|
| Sparse Matrix | Same as sparse vector but in matrix structure whose non-zero values are stored in a Compressed Sparse Column (CSC) format in column-major order.
Sample matrix is as shown below having size (3, 2) will have the size specified followed by:
9.0 0.0 0.0 8.0 0.0 6.0 Sample code:
|
| Distributed Matrix | It has long-typed row and column indices and double-typed values. The data is stored as RDD so they can be distributed across machines. Note, changing data type of distributed matrix afterwards is an expensive operation as it requires a global reshuffle of whole data |
| Row Matrix | It is a row-oriented distributed matrix without meaningful row indices. Each row is a local vector and they are backed by the RDD. Since each row is a local vector it is recommended to have limited number of columns
Sample code:
|
| Indexed Row Matrix | Similar to RowMatrix but with meaningful row indices backed by RDD of indexed rows. You can convert it to RowMatrix by dropping the indices.
Sample code:
|
| Coordinate Matrix | Distributed matrix backed by the RDD of entries where each entry is a tuple of (i: Long, j: Long, value: Double), where i is the row index, j is the column index, and value is the entry value. A CoordinateMatrix should be used only when both dimensions of the matrix are huge and the matrix is very sparse.
Sample code:
|
| Block Matrix | Distributed matrix backed by an RDD of MatrixBlocks, where a MatrixBlock is a tuple of ((Int, Int), Matrix), where the (Int, Int) is the index of the block, and Matrix is the sub-matrix at the given index with size rowsPerBlock x colsPerBlock. It can be created from an IndexedRowMatrix or CoordinateMatrix by calling toBlockMatrix.
For analogy standpoint compare it to Tensors for creating an n-dimensional matrix. Sample code:
|
Source: https://spark.apache.org/docs/2.3.0/mllib-data-types.html