Type Inference First thing to understand about Scala is that it is a Dynamically Typed Language which means that the data type of the values or variables are deduced at runtime. scala> val a = 10.0 a: Double = 10.0 Although it is dynamically types, you can still specify the datatype. scala> val b: Double = 10.0 b: Double = 10.0 Being dynamically […]
Understanding Functional Programming with Scala
Introduction Functional languages are those which treat functions as first class citizens. You can identify the validity of first class citizen status for function by checking the following aspects: 1. Can you assign a function to a value or a variable 2. Can you return a function from another function 3. Can you pass function as a parameter to another function Scala supports both Object […]
Principal Component Analysis (PCA)

Principal Component Analysis (PCA) is a process to achieve Dimensionality Reduction which means reducing the number of features or dimensions while retaining the original variance of the whole data set. The new set of principal components have the variance in descending order so that the first component has maximum variance. Data: We will use the same Breast Cancer data we have used in Support Vector Machines […]
Is your bank still shouting from roof-top?
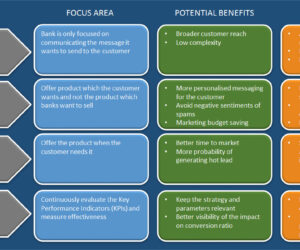
Traditionally banks have relied mainly on the conventional mediums like print, television, radio and postal mails for marketing. With shift in the focus of banks to go digital, banks have also started direct marketing which is reaching customers mainly through SMS, emails, mobile or web channels but still the strategy followed is mainly of broadcast marketing. As per the 2015 Gartner CMO spend survey, the […]
Agglomerative Clustering

Agglomerative and K-means Clustering on US Crime Data Objective: Group US states based on crime data using K-means clustering algorithm and then compare the results with Hierarchical Agglomerative Clustering algorithm. Data Source: 50 US states crime dataset will be used. The Data This data set contains statistics, in arrests per 100,000 residents for assault, murder, and rape in each of the 50 US states in 1973. Also […]
K-means Clustering
K-means Clustering with University Data K-means Clustering is an unsupervised algorithm used to categorise data into groups. The approach followed in the algorithm is as follows: Decide the number of clusters i.e. K. The approach to calculate the ideal value of K is covered further down Set K number of centroids which will be considered as the centre of the K-number of clusters. Note, the […]
What is Machine Learning?

Machine learning is commonly defined as a field of computer science that gives machines the ability to learn without being explicitly programmed. The above statement although correct may not provide clear explanation to someone new to this field. Lets first understand what we mean by the term ‘ability to learn’. In the context of machine learning, it can be considered as a process of applying […]